 imunnic
imunnicMetodología
Durante el desarrollo de este proyecto se utilizará la metodología Combat Agile14. Esta metodología, basada en los principios de Scrum, se adapta a las restricciones específicas del entorno educativo en el que se lleva a cabo el proyecto. Esto incluye consideraciones sobre la configuración del equipo Scrum, las tecnologías disponibles y el contexto de implementación.
Arquitectura
La arquitectura de la aplicación web se basa en un enfoque de arquitectura de full stack15, con un frontend desarrollado en Vue.js y un backend robusto utilizando Spring Boot, Spring Data REST, Spring Security y MongoDB. El frontend en Vue.js ofrece una interfaz de usuario dinámica y receptiva, permitiendo una interacción fluida y eficiente con el backend. A través de llamadas API RESTful, el frontend se comunica con el backend para realizar operaciones basadas en los permisos de los usuarios. El backend maneja la lógica de negocio y las operaciones de datos, utilizando Spring Data REST para exponer una interfaz de datos accesible mediante endpoints RESTful. Spring Security se encarga de la gestión de autenticación y autorización, asegurando que los usuarios solo accedan a los recursos permitidos. MongoDB proporciona un almacenamiento flexible y escalable para los datos de la aplicación. Esta arquitectura permite una integración fluida y escalable entre el frontend y el backend, garantizando una experiencia de usuario segura y eficiente.
Se quiere hacer especial mención a la selección de la Base de Datos como MongoDB, puesto que mientras que el resto de tecnologías han sido las predominantes durante el XLVI Curso para la obtención del Diploma Militar de Informática, pero las bases de datos NO-SQL no han tenido tanto volumen de horas.
A la hora de la definición de un modelo de datos, la primera de las opciones planteadas fue un modelo de datos relacional, con una estructura parecida a la descrita a continuación:
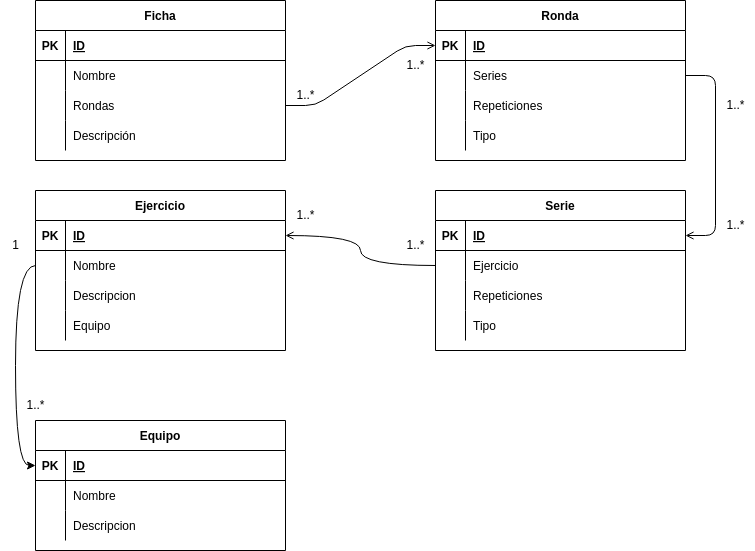
Al plantear este modelo, surgen una serie de problemas:
- Alta necesidad de comunicación con la API: Cada vez que se quiera recuperar una ficha, es necesario solicitar la información de la ficha en cuestión, posteriormente, recuperar y solicitar la información de todas las rondas, posteriormente, de cada una de las rondas recuperar y solicitar las series y lo mismo para recuperar los ejercicios. Toda esta información debería ser mostrada a un usuario que acceda a ver una ficha por lo que para poder mostrarla habría que realizar todas esas peticiones a la API y esperar la respuesta.
-
Se almacena información que no es estrictamente necesaria tener almacenada:
Las rondas y las series no necesitan reutilización en un futuro. Es posible la repetición de las mismas, pero la combinatoria es tan alta que no merece la pena el almacenamiento de las mismas. - Alta variabilidad de las fichas: No todas las fichas están orientadas a lo mismo, algunas están orientadas a calentamientos, otras a la parte fundamental y otras a la vuelta a la calma. Habrá fichas que solo posean una ronda con una serie y otras que tengan una cantidad importante.
Dados estos tres problemas, que se encuentran ordenados por prioridad, podría salvarse el primero utilizando un objeto que devuelva solo los datos requeridos, aunque la carga de programación sería bastante grande. Sin embargo, esto no resolvería los otros dos problemas, que, en principio, no tendrían solución. Se necesitaría almacenar la información de rondas y series y la estructura para las fichas debería ser única.
Sin embargo, al plantear una Base de Datos no relacional, estos tres problemas se resuelven. Si bien es cierto que ninguno de ellos es crítico, pueden generar problemas de mantenimiento y administración a largo plazo y utilizar una Base de Datos no relacional lo resolvería. En este caso la selección de la Base de Datos es de MongoDB porque precisamente facilita esa flexibilidad a la hora de almacenar documentos, permite referenciar unos con otros en caso necesario, como por ejemplo con las fichas y los ejercicios mientras que puede almacenar la información de las rondas y las series sin necesidad de un número elevado de consultas a la API. Por todo ello, se considera oportuno trabajar con MongoDB como gestor de base de datos.
Calendario
El desarrollo de CENTAURI se implementará en sucesivos sprint hasta que la pila de trabajo del producto haya quedado vacía.
Queda por tanto, el siguiente calendario:
| Plazos | Etapa |
|---|---|
| 02-20 septiembre | Estudio de viabilidad |
| 23 septiembre - 11 octubre | Sprint 1 |
| 11-25 octubre | Sprint 2 |
| 28 octubre - 22 noviembre | Sprint 3 |
| 28-29 de noviembre | Exposición del proyecto |
Tecnologías y entornos de desarrollo/despliegue
-
Frontend: se implementará en HTML5, CSS y JavaScript a través del framework Vue.js.
-
Backend: la API se desarrollará en lenguaje Java haciendo uso del framework Spring Boot.
-
Base de Datos: como gestor de base de datos se utilizará MongoDB.
-
IDEs: Eclipse y Visual Studio Code.
-
Otras herramientas: Git para el control de versiones y Postman para el test de la API.
Equipo Scrum
- Scrum Master: Capitán D. Vicente Espiñeira Cachaza.
- Product Owner y desarrollador: Capitán D. Ignacio Ovidio Muñoz Nicolás.